{site}
Sample Usage
Page Domain: {site:domain}
Page Path: {site:path}
Page Title: {site:title}
Quick Overview VideoSettings
Setting Name Type Description Positional text The type of page information to get. frame self/top Which frame to get information from (defaults to top). selector text A CSS selector for use with the html or text types. multiple yes/no When selector is specified, whether to return multiple results or just the first result (defaults to no). page string When page is specified, the {site} command will read data from tabs whose URLs match the given page URL. select yes/no/ifneeded When page is specified, this setting controls whether to show the tab selector. yes will always show the tab selector. no does not show the tab selector and only matches the current page. ifneeded (default) shows the tab selector only when multiple tabs are matching the given page pattern. group string Allows different {site} commands with the same page setting to read data from different tabs. General Command Settings trim yes/no/left/right If yes whitespace is removed before and after the command. If left, only whitespace to the left is removed. If right, only whitespace to the right is removed.
| Setting Name | Type | Description |
|---|---|---|
| Positional | text | The type of page information to get. |
| frame | self/top | Which frame to get information from (defaults to top). |
| selector | text | A CSS selector for use with the html or text types. |
| multiple | yes/no | When selector is specified, whether to return multiple results or just the first result (defaults to no). |
| page | string | When page is specified, the {site} command will read data from tabs whose URLs match the given page URL. |
| select | yes/no/ifneeded | When page is specified, this setting controls whether to show the tab selector. yes will always show the tab selector. no does not show the tab selector and only matches the current page. ifneeded (default) shows the tab selector only when multiple tabs are matching the given page pattern. |
| group | string | Allows different {site} commands with the same page setting to read data from different tabs. |
| General Command Settings | ||
| trim | yes/no/left/right | If yes whitespace is removed before and after the command. If left, only whitespace to the left is removed. If right, only whitespace to the right is removed. |
Getting information from a web page is extremely useful in further automating your snippets.
For example, if you're using Text Blaze on your chat application, you could set it up to get specific information, like a name, email, or something else, present on the web page to use in your snippet
Throughout this documentation page, you will get several examples to help you see the {site} command's usefulness.
Getting specific information from a web page
The first setting supported by the {site} command is a positional setting that tells the command the type of information to get from the web page.
The table below displays the different supported values that this command takes:
| Type | Description | Example for url https://test.com/my/page?foo=1#part |
|---|---|---|
| url | The full url of the page. | https://test.com/my/page?foo=1#part |
| domain | The domain of the url. | test.com |
| path | The path of the url. | /my/page |
| protocol | The protocol of the url. | https |
| query | The query of the url. | ?foo=1 |
| hash | The hash of the url. | #part |
| html | The html of the webpage. | <html>...</html> |
| text | The text of the webpage. | Welcome to... |
| title | The title of the webpage. | Site Title |
| fieldtext | The text of the focused textfield. | Hi there hello! |
| selection | The currently selected text. | there |
| fieldleft | The text to the left of the cursor in the focused textfield. | Hi |
| fieldright | The text to the right of the cursor in the focused textfield. | hello! |
Capitalization is important. For example, you can use {site: url} to get the web page's URL, but doing {site: URL} will not work.
Getting Information from the URL
The url, domain, path, protocol, query, and hash values are all concerned with getting information the URL of the current web page.
Here are the properties you can retrieve information for represented visually:

This information can be used in a variety of ways. For example, you could combine it with the {if} command to only insert information if you're on a specific part of the web page.
Including the Page Contents in your Snippet
The next two values that you can use in the {site} command's positional setting are text and html.
These two are not related to the URL, but instead get contents of the web page.
You can use them to dynamically populate parts of your snippets.
For example, if you use a Text Blaze snippet within your email application, you could use it to include information about the email recipient's name in your snippet.
To illustrate the usage of text and html in the {site} command, we're going to consider some HTML typical of what you might see on a site:
Sample HTML:
<div class="user-info">
Name: <span class="name">John Smith</span>
<ul class="favorites">
<li>Oreos</li>
<li>Twizzlers</li>
<li>Snickers</li>
</ul>
</div>
How the above sample HTML would render in a web page:
We can use the {site} command to extract information from this sample. {site: text} and {site: html} will give you access to all the contents of the page. For example:
Text for whole page (truncated for readability): {=substring({site: text}, 1, 50)}...
Also, one very important thing to note is that the text type pulls text content from the page. This does not include contents inside of <input> or <textarea> HTML tags. To include the contents of these elements, you need to specify a selector that specifically selects one of these elements and not a parent element. We'll review selectors in the next section.
Getting specific parts of a page
Using {site: html} or {site: text} will give you the entire contents of the page.
Generally, though you just want to get a specific part of the contents of the page, like a name or address. Text Blaze has two ways to do that: CSS Selectors and Regular Expressions.
If you do use html or text as the value for the {site} command's positional setting you have access to 2 additional named settings.
Those named settings are selector and multiple. These 2 named settings are concerned with how to get the contents of the page.
Using CSS Selectors to Get Part of the Page
One way that Text Blaze can access specific parts of the page is with CSS selectors. CSS selectors provide a very concise method of getting specific parts of a page.
The details of CSS selectors are out of the scope of this documentation, and we refer you to this website to understand them in more detail.
Fortunately, for most use cases, Text Blaze can automatically create the right selector for you with point and click. Just use the "Select from website" feature of Text Blaze and click on the desired part of the page.
Here is an animation showing how this works:
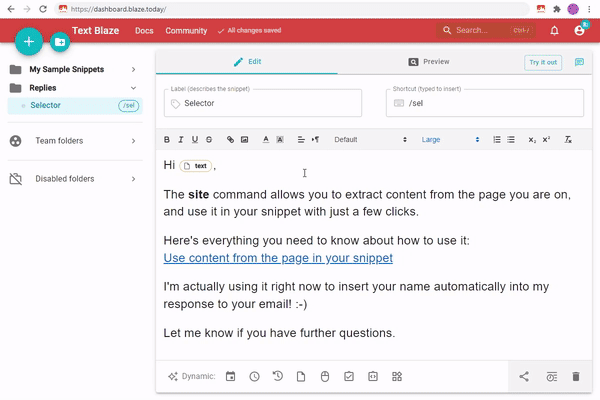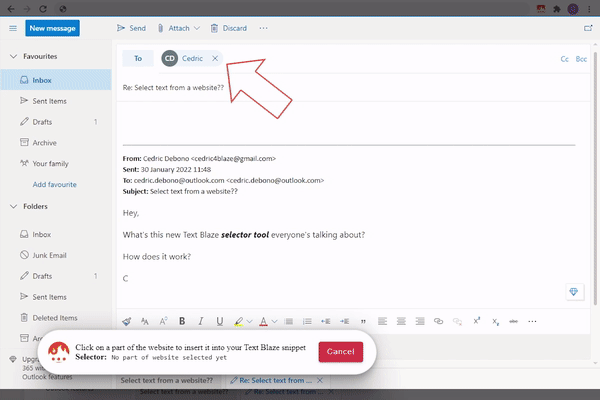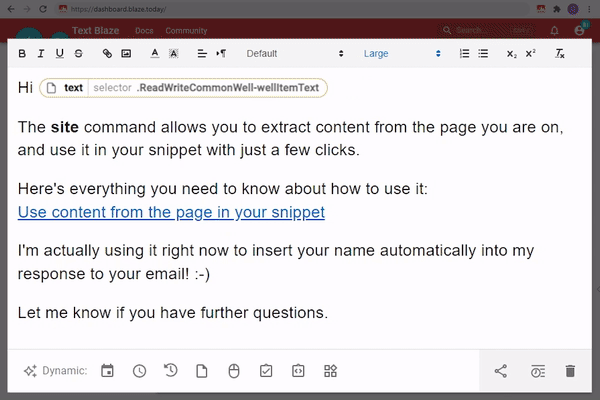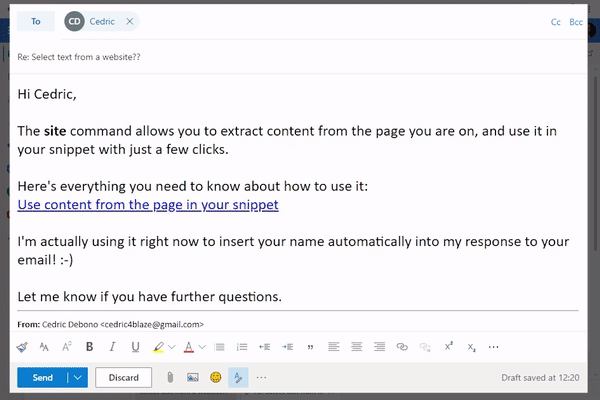
Once you have your selector, the snippet automatically populates its contents when used. For example, in the html sample from the previous section, you can get the name using a CSS selector. You can also use another CSS selector to get different parts of the favorites list.
Using a CSS selector to get the first favorite item: {site: text; selector=.user-info .favorites li}
Reading information from any tab
The {site} command supports pulling information from any tab in Chrome and inserting it into your current tab.
For example, when writing an email to a client, you can:
- Use your snippet in the email webpage
- Use {site} to pull client information from your CRM open in a different Chrome tab
This is the default behavior in Text Blaze and requires no additional setup.
Text Blaze matches your open Chrome tabs using the wildcard pattern in the page setting. For example, setting page to https://blaze.today/commands/* will match this page but not https://blaze.today/docs/
When more than one Chrome tab matches the page setting, Text Blaze shows a tab strip in your form window:
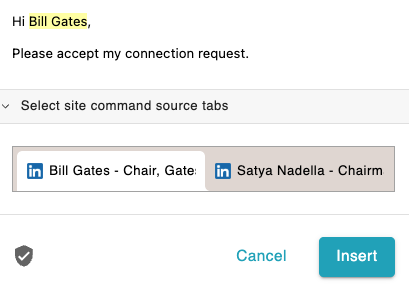
You can choose which tab to use from this tab strip.
Controlling the tab selector
The select setting controls when this tab strip appears. It can have one of these three values:
yes: Always shows the tab selector, even with just one matching tab.no: Never shows the tab selector. The {site} command will show an error if thepagepattern doesn't match the current page.ifneeded(default): Only shows the tab selector when multiple tabs match.
By default, all {site} commands with the same page setting will pull data from the same tab. For example, {site: text; page=https://blaze.today/*} and {site: url; page=https://blaze.today/*} will always use the same Chrome tab.
You can use the group setting to pull data from different tabs even with the same page pattern. For example, the following two commands {site: text; page=https://blaze.today/*; group=First item} and {site: text; page=https://blaze.today/*; group=Second item} can pull data from two different Chrome tabs (both matching the same page pattern).
Getting more than one element with the multiple setting
Notice how in the above CSS selectors example that using .user-info .favorites li gets the first item in the favorites list even though multiple elements have the same CSS selector.
There is where the named setting multiple comes in. If multiple is no or omitted only the first match will be returned.
If multiple is yes all the matches will be returned as a list.
Handling Errors
If multiple is no and there is no match for that specific CSS selector on the web page you're using the snippet on, an error will be displayed.
Text Blaze provides you with catch(), a predefined function to help you deal with an error scenario. You can use it to provide a default value in an error case in your formulas:
Error caught and replaced with another value: {=catch({site: text; selector=.does-not-exist}, "My Default Value")}
If multiple is set to yes, on the other hand, and there is no match, Text Blaze will return an empty list ([]).
Controlling where information is loaded from using the frame setting
Web pages can embed other web pages (called 'frames'). If you use a Text Blaze snippet inside of a frame, you can use the frame named setting to load information either the frame (by setting the frame setting to self) or from the web page embedding the frame (by setting the frame setting to top).
If Text Blaze is used in a normal web page without frames, both self and top are equivalent. Text Blaze defaults to top. This will return the URL you see in Chrome's URL bar.
Using Regular Expressions to Get Part of the Page
Regular expressions are a powerful way to search through text and find specific patterns of text.
For example, if you're looking for a phone number or an email address (both pieces of textual content that follow a specific pattern), then regular expressions can help you find those.
The following video will help you further understand how Regular Expressions work.
Text Blaze has an extractregex() predefined function that takes two string parameters.
If you use {site: text} or {site: html}, then you can use Regular Expressions as an alternative to CSS selectors to retrieve a specific part of the web page.
For example, if you want to get the name from the html sample in the previous section, you can use the following regular expression: "Name: ([\w ]+)".
This tells Text Blaze, that we want all the text after the text "Name: " that consists of spaces or letter characters.
Name from the page: {=extractregex({site: text}, "Name: ([\w ]+)")}
You can read more about regular expressions in our Blaze Formula Language Reference, reading our non-scary guide on the community forums, and watching the above video. Also, there are some great online resources you can use to learn more about them.
Reading data based on user selection in a page
The selector and xpath settings allow you to read data from a fixed element. You can also instead read data from the page based on the active user selection. For example: assume that you have a textbox with this text "Hi there hello!" (without quotes). Now, you have selected the word "there" with the mouse. Now, you can check the following four {site} commands:
{site: selection}- outputs the currently selected text, whether it is inside or outside a textbox. In this case, it outputs "there" (without quotes).{site: fieldtext}- outputs the text of the focused textfield. In this case, it outputs "Hi there hello!" (without quotes).{site: fieldleft}- outputs the text to the left of the cursor in the focused textfield. In this case, it outputs "Hi" (without quotes).{site: fieldright}- outputs text to the right of the cursor in the focused textfield. In this case, it outputs "hello!" (without quotes).
As the names suggest, {site: selection} works whether or not a textfield is focused, whereas the other three commands output blank if no textfield is focused.
Note that all four commands can be combined with the page setting to read data from another webpage in another browser tab.